
Nos dias de hoje, os dados são considerados o novo petróleo, e a capacidade de extrair insights valiosos de conjuntos de dados massivos é uma habilidade crucial. Surge o KDD, ou Descoberta de Conhecimento em Bancos de Dados, como uma abordagem crucial para transformar dados brutos em informações úteis e acionáveis. Neste artigo, vamos explorar mais sobre o KDD e como ele se tornou uma ferramenta essencial no mundo da ciência de dados.
Conteúdo
O que é KDD?
O processo de Knowledge Discovery in Databases (KDD) é uma abordagem sistemática e iterativa para transformar dados brutos em conhecimento útil. O KDD mais do que uma metodologia específica. Ele representa um conjunto de etapas inter-relacionadas e técnicas aplicadas na descoberta de conhecimento a partir de grandes conjuntos de dados. É um processo complexo que envolve várias etapas, desde a seleção de dados até a interpretação dos resultados. A ideia fundamental por trás do KDD é descobrir padrões, conhecimento útil e informações ocultas nos dados. Ele não se limita apenas à extração de informações, mas abrange toda a jornada de descoberta, desde a pré-processamento dos dados até a avaliação dos resultados.
Etapas do Processo KDD
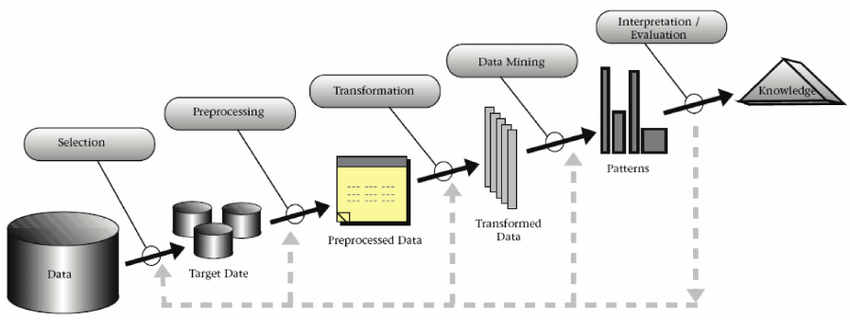
Para garantir o sucesso na descoberta de conhecimento, é crucial seguir seis etapas fundamentais que orientam o processo de maneira eficaz. Essas etapas formam a espinha dorsal, assegurando que cada passo seja cuidadosamente delineado para obter resultados significativos. Vamos agora explorar detalhadamente cada uma das seis etapas, proporcionando insights valiosos sobre como conduzir uma análise bem-sucedida na busca e aplicação do conhecimento por meio da descoberta de dados.
Etapa 1: Seleção de Dados
A fase de seleção de dados é crucial para determinar quais conjuntos de dados serão utilizados no processo de KDD. Por exemplo, em um contexto empresarial, se estamos buscando entender padrões de compra de clientes, poderíamos selecionar dados de transações, histórico de compras e informações demográficas. Uma seleção adequada de dados é essencial para garantir que o KDD gere resultados relevantes e aplicáveis.
Etapa 2: Pré-processamento de Dados
Após a seleção, os dados geralmente precisam ser limpos e preparados para análise. Isso envolve lidar com valores ausentes, eliminar duplicatas e corrigir erros nos dados. Por exemplo, se um conjunto de dados de vendas contiver registros com valores nulos para o preço dos produtos, seria necessário decidir se os registros devem ser excluídos, preenchidos com a média dos preços ou abordados de outra maneira.
Etapa 3: Transformação de Dados
A transformação de dados é necessária para moldar os dados de maneira que os algoritmos de mineração de dados possam extrair informações significativas. Isso pode incluir normalização de dados, conversão de formatos, criação de novas variáveis ou agregação de dados. Se estivermos analisando dados de vendas diárias, poderíamos agrupá-los por semana para identificar padrões semanais de vendas.
Etapa 4: Mineração de Dados
A etapa central do KDD, a mineração de dados, utiliza algoritmos para identificar padrões e informações nos dados. Exemplos incluem a aplicação de algoritmos de associação para descobrir relações entre itens frequentemente comprados juntos ou o uso de algoritmos de classificação para prever se um cliente é propenso a comprar um produto com base em seu histórico de compras.
Algoritmos Comuns Utilizados na Mineração de Dados
Na mineração de dados, diversos algoritmos estão disponíveis para desvendar informações valiosas. Cada um possui suas próprias características e serve a propósitos específicos. Esses algoritmos ajudam a prever futuros comportamentos, encontrar conexões escondidas e agrupar dados similares. Escolher o algoritmo certo é fundamental para desvendar o potencial escondido nos dados. Abaixo segue uma amostra dos algoritmos mais comuns utilizados.
- Árvores de Decisão:
- Identificam padrões hierárquicos nos dados, frequentemente usadas em classificação.
- K-Means:
- Agrupa dados em clusters com base em similaridades, útil para segmentação de mercado.
- Regressão Linear:
- Modela a relação entre variáveis para prever valores numéricos.
- Regras de Associação:
- Identificam relações frequentes entre itens, como no caso do algoritmo Apriori para cestas de compras.
Em breve, compartilharei novos posts abordando cada tema e fornecendo códigos práticos para cada algoritmo. Fiquem atentos para não perder nenhum conteúdo. Aguardem por insights e conhecimentos aplicados diretamente em seus projetos de mineração de dados! 🚀✨
Etapa 5: Avaliação
Após a mineração de dados, os resultados precisam ser avaliados quanto à sua relevância e confiabilidade. Por exemplo, se estamos tentando prever a demanda futura de produtos, podemos avaliar a precisão do modelo comparando as previsões com os dados reais. Essa etapa ajuda a garantir que as descobertas sejam válidas e úteis para os objetivos definidos.
Etapa 6: Interpretação
A interpretação dos resultados é crucial para transformar padrões identificados em conhecimento acionável. No contexto de vendas, se a mineração de dados revelar que certos produtos são frequentemente comprados por clientes que compram determinados outros produtos, essa informação pode ser usada para estratégias de marketing direcionadas ou otimização de layout em lojas físicas.
Exemplo Prático: Previsão de Churn em Telecomunicações
Agora que entendemos todas as etapas do processo do KDD, vamos considerar um exemplo prático do seu em uma empresa de telecomunicações. O objetivo é prever o churn (cancelamento de serviço) dos clientes.
- Seleção de Dados: Coletamos dados sobre os clientes, incluindo tempo de serviço, tipos de serviço utilizados, reclamações anteriores e histórico de pagamentos.
- Pré-processamento de Dados: Lidamos com valores ausentes, removemos duplicatas e corrigimos erros. Por exemplo, se alguns clientes tiverem registros de tempo de serviço inconsistentes, esses registros seriam corrigidos ou removidos.
- Transformação de Dados: Criamos variáveis como a média de reclamações nos últimos seis meses e a proporção de pagamentos atrasados. Essas variáveis podem ajudar a capturar padrões mais complexos.
- Mineração de Dados: Aplicamos algoritmos de machine learning para identificar padrões que indicam a probabilidade de um cliente cancelar o serviço nos próximos meses.
- Avaliação: Avaliamos a precisão do modelo usando dados de clientes anteriores, comparando as previsões do modelo com os casos reais de churn.
- Interpretação: Identificamos os principais fatores que contribuem para o churn, como reclamações frequentes ou histórico de pagamentos inconsistentes. Essas descobertas podem orientar estratégias para reter clientes.
Além desse exemplo prático, gostaria de compartilhar um artigo que elaborei alguns anos atrás, no qual apliquei a abordagem do KDD durante seu desenvolvimento. O título deste artigo é: Abordagem para Descoberta de Conhecimento em Instrumentos Avaliativos de Organizações de Ensino Superior.
Conclusão
O KDD é uma abordagem prática e eficaz para extrair conhecimento útil dos dados. Do início ao fim, desde a escolha dos dados até a aplicação dos algoritmos, cada etapa desempenha um papel essencial na transformação de dados em insights valiosos. O KDD capacita profissionais a tomar decisões informadas e inovar com base em dados reais.
Se gostou compartilhe com um amigo!
Grande abraço!